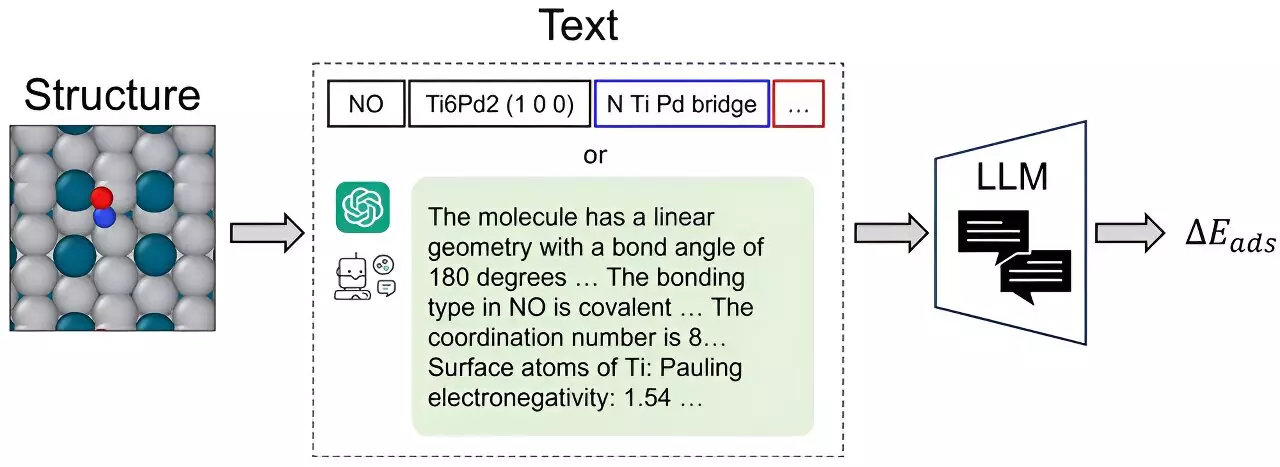
Catalysts play an integral role in various processes, from converting milk into yogurt to producing Post-It notes. The search for optimal catalyst materials often involves time-consuming experiments and complex quantum chemistry calculations. To simplify this process, scientists have turned to graph neural networks (GNNs) to predict the structural intricacies of atomic systems. However, researchers at Carnegie Mellon University’s College of Engineering have developed CatBERTa, a transformative energy prediction Transformer model. This cutting-edge approach utilizes a large language model (LLM) to predict molecular properties, offering a new avenue for catalyst modeling.
Traditionally, catalyst modeling required painstaking data conversion and preprocessing to prepare 3D atomic structures for graph-based analysis. However, CatBERTa eliminates this need by utilizing natural language processing capabilities. This model directly employs text without any preprocessing, simplifying the prediction of properties in the adsorbate-catalyst system. This approach not only enhances interpretability but also enables seamless integration of observable features into the data. As Janghoon Ock, a Ph.D. candidate in Amir Barati Farimani’s lab, emphasizes, CatBERTa serves as a complementary approach to existing GNN methods for catalyst modeling.
Despite being a novel approach, CatBERTa has demonstrated remarkable predictive accuracy. In fact, it achieves comparable results to earlier versions of GNNs, while surpassing their error cancellation abilities. This remarkable performance is particularly evident when the model utilizes limited-size datasets for training. The team’s focus on adsorption energy demonstrates the adaptability of CatBERTa. By leveraging an appropriate dataset, this approach can extend to predicting other properties, such as the HOMO-LUMO gap and stabilities related to adsorbate-catalyst systems.
The utilization of a transformer model like CatBERTa offers more than just predictive accuracy. Researchers can gain valuable insights through self-attention scores, which enhance the comprehension and interpretability of the framework. By examining these scores, scientists can better analyze the relationships between different components within the catalytic system. While CatBERTa may not replace state-of-the-art GNNs, it certainly provides an alternative and complementary approach, as the saying goes, “The more the merrier.”
Streamlining Catalyst Discovery
The integration of extensive language models with catalyst discovery aims to streamline the process of effective catalyst screening. By leveraging the capabilities of CatBERTa, researchers can significantly reduce the time and effort required for catalyst identification and selection. Moreover, the model’s innate interpretability allows researchers to incorporate observable features seamlessly, providing a holistic understanding of catalyst behavior.
Future Directions
Despite CatBERTa’s impressive performance, the researchers behind this model are dedicated to further enhancing its accuracy. Continuous improvements in the training process will undoubtedly lead to even more robust predictions. Furthermore, the versatility of this approach opens doors for exploring additional properties beyond adsorption energy, thus expanding the scope of its application in catalyst discovery.
CatBERTa represents a significant advancement in catalyst modeling by leveraging the power of language models. Its ability to directly process natural language eliminates the need for meticulous preprocessing, while providing accurate and interpretable predictions. With further refinements and explorations into its capabilities, CatBERTa holds great promise for revolutionizing the field of catalyst discovery.
Leave a Reply