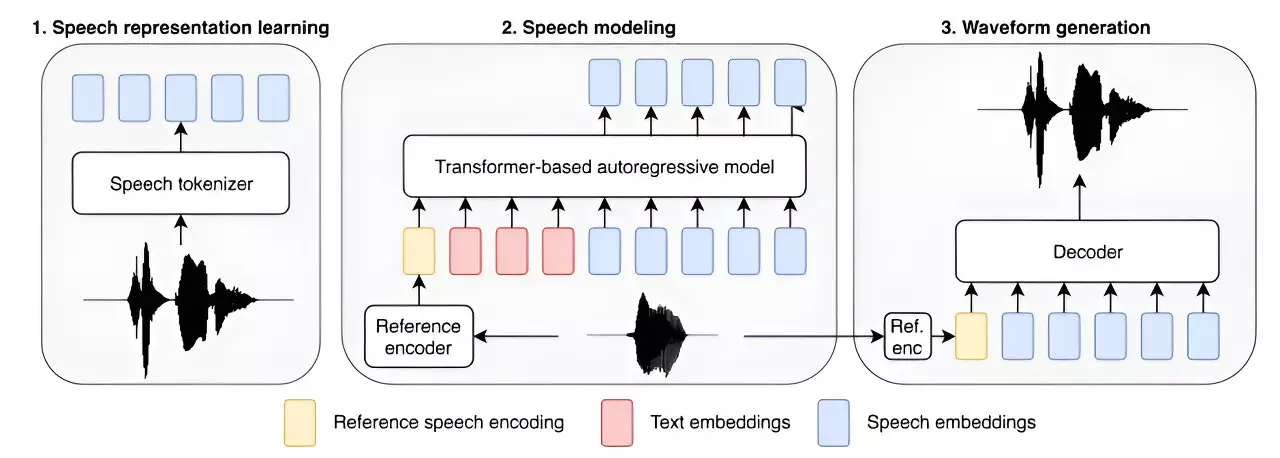
Artificial intelligence researchers at Amazon AGI have recently unveiled a revolutionary text-to-speech model that is being heralded as the largest of its kind. This model, known as Big Adaptive Streamable TTS with Emergent abilities (BASE TTS), boasts an impressive 980 million parameters and was trained using a massive dataset of 100,000 hours of recorded speech.
The development of BASE TTS represents a significant advancement in the field of text-to-speech technology. By increasing the number of parameters and expanding the training dataset, the researchers aimed to enhance the model’s ability to accurately pronounce words and phrases in multiple languages. In addition to English, the model was trained on examples of spoken words and phrases from other languages, enabling it to correctly pronounce foreign terms and expressions.
One of the key findings from the research conducted by the Amazon AGI team was the emergence of what is known as an “emergent quality” in the model. This phenomenon, which occurs when an AI application reaches a higher level of intelligence, was observed when the model reached 150 million parameters. The emergence of this quality was characterized by the model’s ability to utilize compound nouns, express emotions, incorporate foreign language terms, apply paralinguistics and punctuation, and ask questions with proper emphasis.
Despite the groundbreaking nature of the BASE TTS model, the Amazon AGI team has decided not to release it to the public due to concerns about potential unethical use. Instead, they plan to utilize the model as a learning tool to further refine and improve text-to-speech applications in the future. By leveraging the insights gained from this project, the researchers hope to enhance the human-sounding quality of text-to-speech technology across various applications.
Leave a Reply