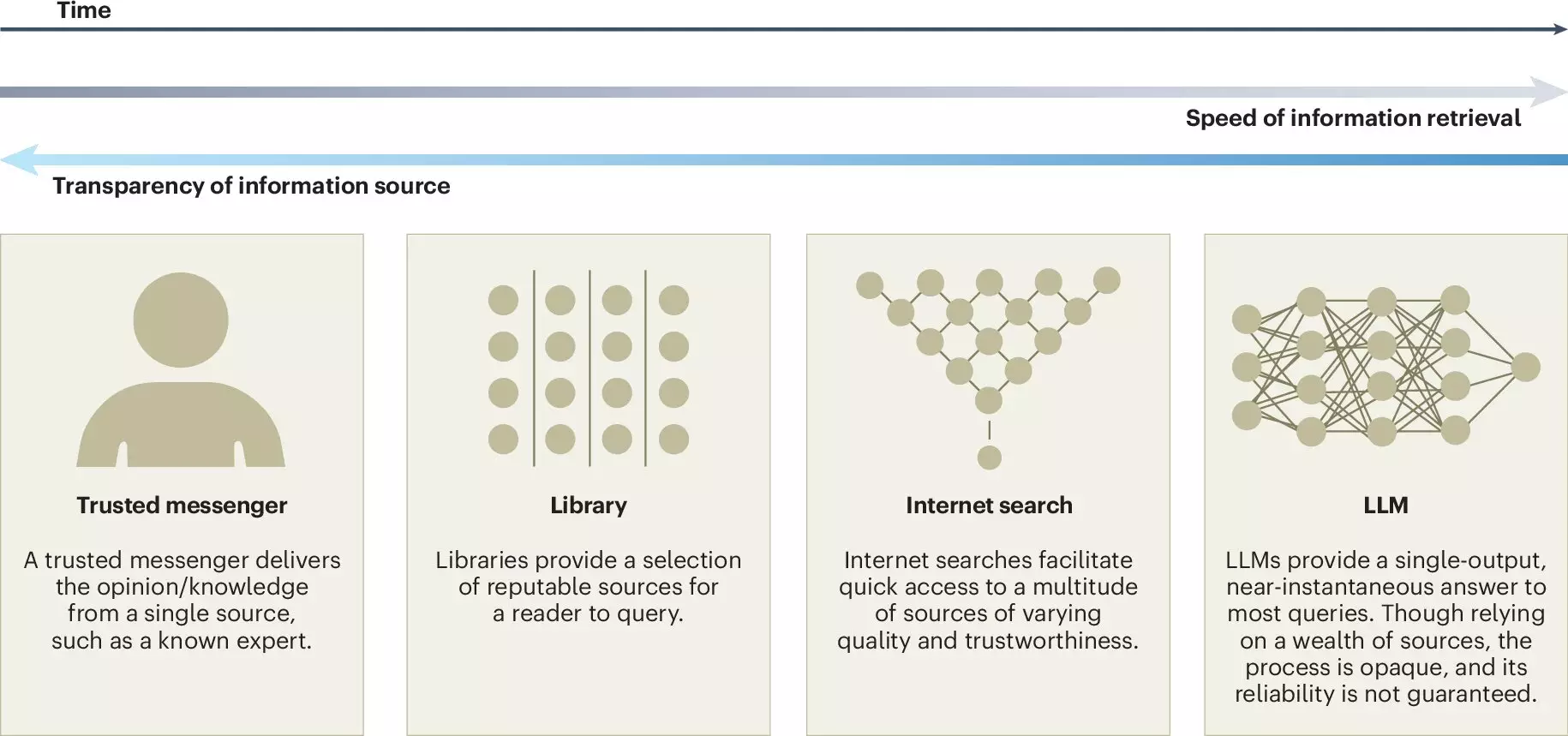
In recent years, large language models (LLMs) have surged in prominence within the landscape of artificial intelligence, becoming ubiquitous in applications ranging from virtual assistants to customer service chatbots. Models such as ChatGPT have transformed the way we interact with information, gearing our day-to-day tasks towards a faster, more efficient processing of language and data. A recent article published in the esteemed journal Nature Human Behaviour addresses the duality of opportunities and challenges presented by LLMs, especially concerning their influence on collective intelligence—the concept of pooling individual knowledge for greater decision-making capacity. This evolving technology urges us not only to explore its potential but to remain vigilant of the accompanying risks that may undermine human collaboration and understanding.
At its core, collective intelligence is the amalgamation of individual insights and skills, leading to outcomes that surpass those achievable by solitary efforts. In scenarios like team projects or community engagements, this intelligence manifests itself in diverse settings ranging from workplaces to vast platforms like Wikipedia. LLMs have demonstrated a capacity to augment this collective intelligence. By providing translation capabilities or summarizing discussions, these models lower barriers to participation, ensuring a more inclusive approach to dialogue.
As identified by Ralph Hertwig, a co-author of the study from the Max Planck Institute for Human Development, this enhancement of collective intelligence hinges on harnessing LLMs in a manner that leverages their capabilities. For instance, they can facilitate creative brainstorming sessions or assist in parsing through multiple viewpoints to foster consensus. The authors suggest that these models could act as a bridge between varying perspectives, enriching the discussions by presenting both dominant and minority views in a balanced manner—if used correctly.
However, the integration of LLMs into collective processes presents its own set of challenges. A predominant concern is that these systems may create a dependency that discourages human contributions to established knowledge bases such as Wikipedia or Stack Overflow. If users turn increasingly towards proprietary LLMs for information, the foundation of open knowledge could be compromised. The risk of alienating individual contributions poses a threat to the very fabric of collaborative knowledge, creating a homogenous landscape where diverse perspectives may go unrepresented.
One major implication of this reliance is the emergence of a false consensus—a scenario in which a perceived majority opinion overshadows minority views. This phenomenon, known as pluralistic ignorance, can lead to misunderstandings within collective discussions, suggesting that everyone is in agreement when, in reality, varied opinions exist. As pointed out by Jason Burton, the study’s lead author, the vast repositories from which LLMs draw their knowledge may marginalize underrepresented perspectives, distorting our understanding of consensus in group dynamics.
Given these intertwined challenges, the article pushes for a proactive approach in integrating LLMs within environments that depend on collective intelligence. The authors advocate for increased transparency in the creation of LLMs, urging developers to detail their training data sources. External audits could play a critical role in assessing the reliability of these models, ensuring that their operations do not inadvertently suppress diverse perspectives and reinforce biases.
Managing and monitoring LLM development is essential to understanding how to harness these technologies responsibly. The need for well-defined guidelines on how LLMs should evolve in response to challenges such as knowledge homogenization and representation remains a critical area for further exploration.
In exploring the influence of large language models on collective intelligence, the findings highlighted in the article resonate with a broader narrative about the intersection of technology and human capability. With the right balance, LLMs could revolutionize how we collaborate and share knowledge. Yet, as we embrace these advancements, we must remain cognizant of their potential pitfalls; the challenge resides not only in maximizing the benefits of LLMs but also in safeguarding the richness of our collective insights.
Ultimately, as we move into an era where AI shapes the information environment, our approach must be tailored to foster inclusivity, transparency, and trust in these technological tools. Engaging in ongoing dialogue about the ethical implications of LLMs will empower researchers, policymakers, and users alike to cultivate a landscape that enhances rather than diminishes our collective intelligence. Through careful navigation of these evolving technologies, we can ensure that human insight continues to thrive in synergy with the advancements of artificial intelligence.
Leave a Reply