Deep learning algorithms have gained immense popularity due to their ability to analyze vast amounts of data and extract meaningful patterns. However, the effectiveness of these models hinges on the quality of the datasets used for training. A persistent issue in this context is label noise—incorrect or misleading labels in training data—which can undermine classification capabilities, severely impacting a model’s predictive power. Given the prevalence of such noise in real-world applications, finding robust solutions that enhance the resilience of deep learning models remains a critical area of research.
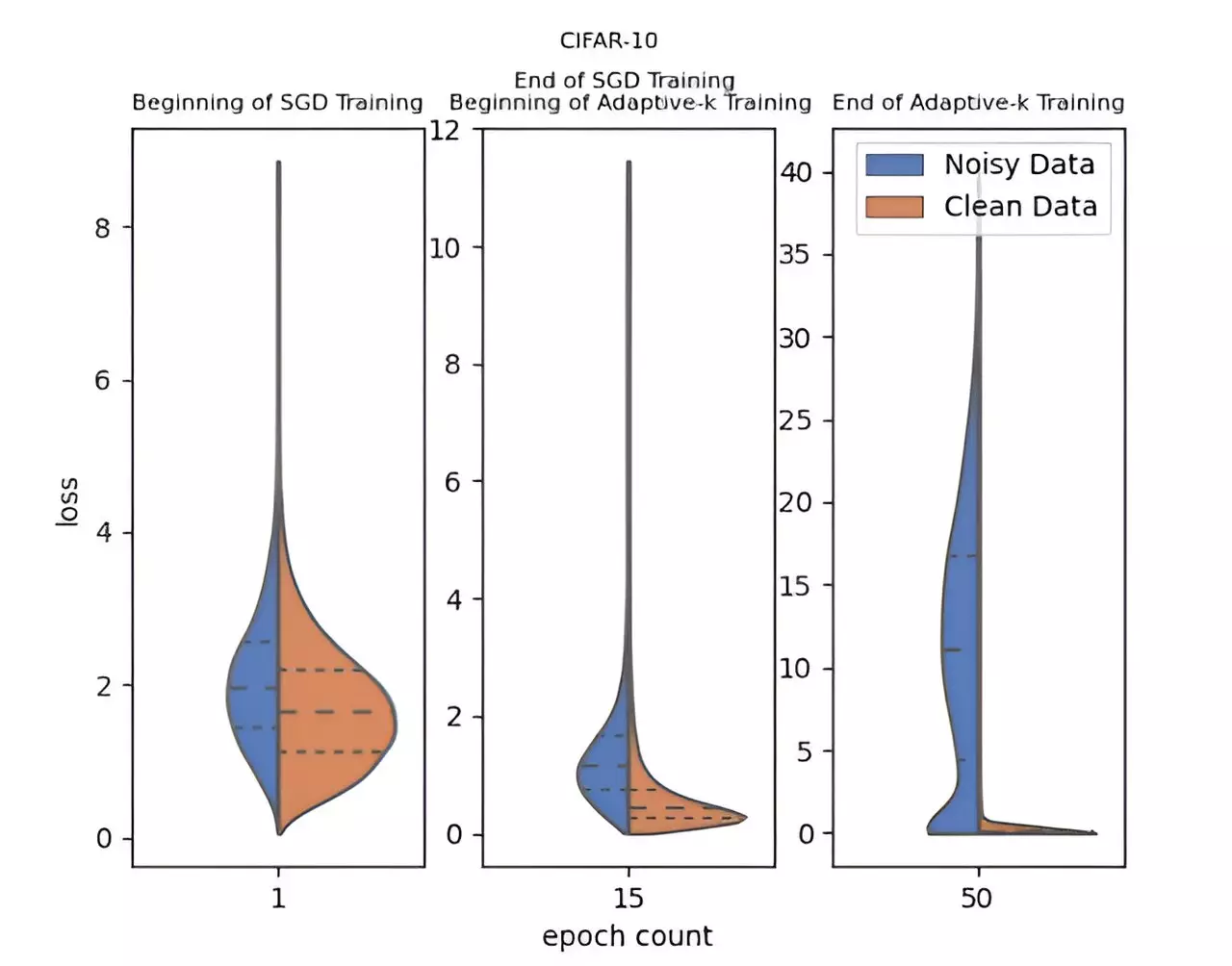
Researchers Enes Dedeoglu, H. Toprak Kesgin, and Prof. Dr. M. Fatih Amasyali from Yildiz Technical University aimed to tackle the problem of label noise with their groundbreaking method known as Adaptive-k. This innovative approach focuses on optimizing the training of deep learning models by adaptively selecting the number of samples used in mini-batches for updates during training. This selective method allows the model to effectively filter out noisy data, ultimately leading to enhanced performance on datasets often plagued by inaccuracies.
What sets Adaptive-k apart from conventional techniques is its simplicity and efficiency. Notably, it does not necessitate prior knowledge about the dataset’s noise level, nor does it require extensive retraining of models or additional time for training—two common hurdles in adaptive learning strategies.
The team conducted extensive experiments to benchmark the performance of Adaptive-k against several other established algorithms, including Vanilla, MKL, Vanilla-MKL, and Trimloss. They compared results in scenarios where it was assumed that all noisy samples were known and excluded (the Oracle scenario), showcasing how close Adaptive-k can come to this ideal situation, where noise is entirely eradicated.
Testing was conducted on a variety of datasets, encompassing both image and text classifications. Remarkably, throughout these tests, Adaptive-k consistently outperformed its peers, demonstrating its robust adaptability to noise. Furthermore, the method integrates well with an array of optimization strategies, including SGD, SGDM, and Adam, thereby enhancing its versatility and applicability across different domains.
Future Directions
The implications of Adaptive-k extend beyond immediate performance improvements. The researchers are dedicated to further refining this method, intending to explore additional applications within the field of machine learning. As technology advances, incorporating more intricate and nuanced approaches could lead to even stronger models capable of handling increasingly complex datasets with inherent noise.
Adaptive-k not only presents a viable solution to the challenge of label noise but also opens avenues for future research, promising to fundamentally change how deep learning models are trained in the presence of noisy data. This method stands as a testament to the potential of innovative thinking in overcoming significant obstacles within the domain of artificial intelligence.
Leave a Reply