Large language models (LLMs) have gained popularity in recent years for their ability to process, generate, and manipulate text in various languages. However, along with their impressive capabilities, LLMs are also known for their tendency to generate hallucinations – responses that are entirely inaccurate, nonsensical, or inappropriate. This raises concerns about the reliability of these models, especially when they are used in critical settings.
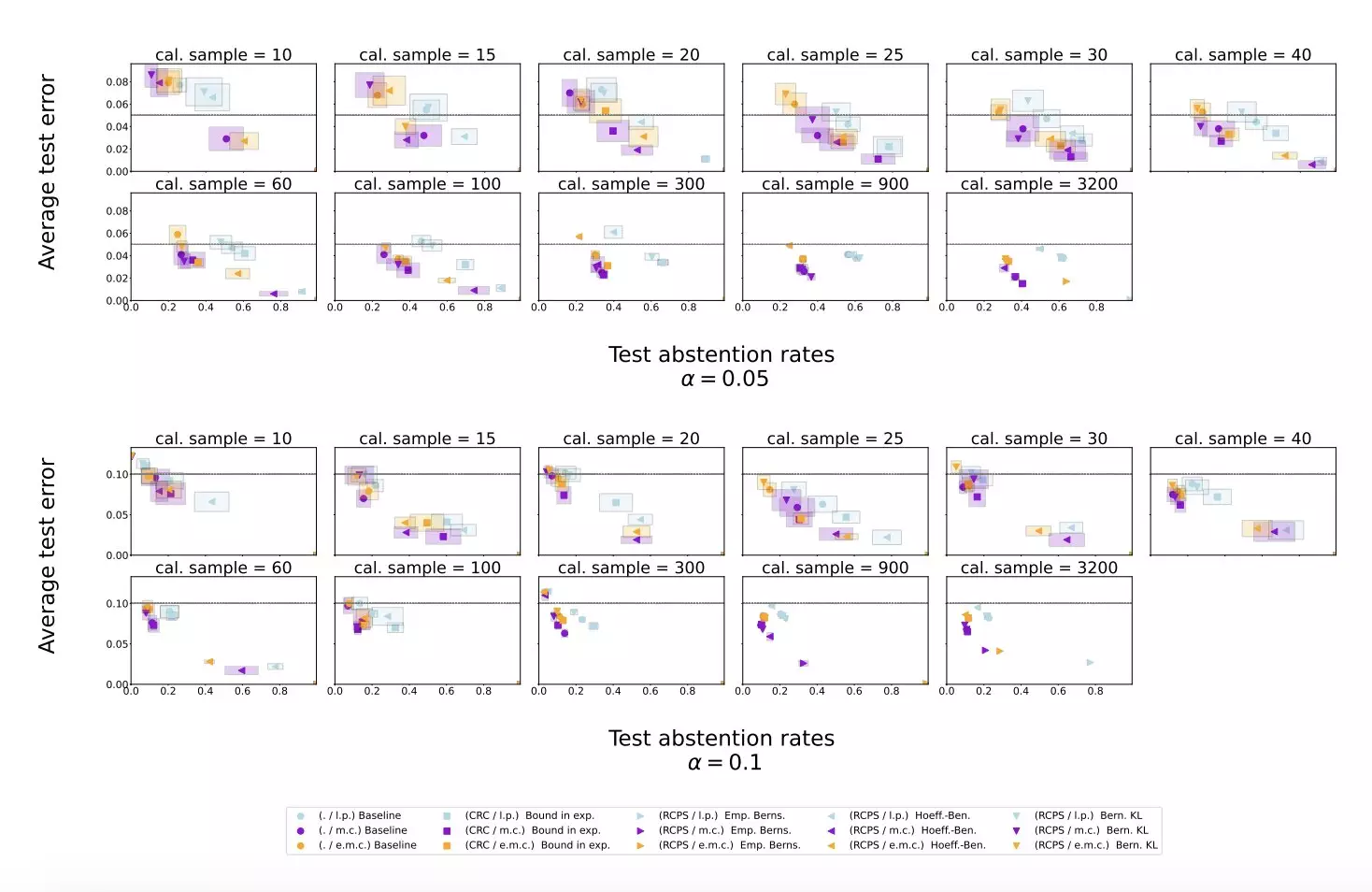
Researchers at DeepMind have recently introduced a novel approach to identify instances where an LLM should abstain from providing a response due to the likelihood of hallucinations. By using the LLM to evaluate its own potential responses and leveraging conformal prediction techniques, the researchers were able to develop a method that reliably bounds the hallucination rate while maintaining a less conservative abstention rate.
The researchers conducted experiments using publicly available datasets and applied their method to Gemini Pro, an LLM developed by Google. The results of the experiments showed that the proposed approach effectively mitigated LLM hallucinations, outperforming simple baseline scoring procedures. This suggests that the new method could significantly improve the reliability of LLMs and prevent them from generating inaccurate or nonsensical responses.
The findings of this study by DeepMind hold promise for the future development of LLMs and their widespread use among professionals worldwide. By addressing the issue of hallucinations, the proposed approach could enhance the credibility and trustworthiness of LLM-generated content. This, in turn, could lead to increased acceptance and adoption of LLMs in various fields and applications.
Moving forward, it is essential to continue refining and developing methods to improve the reliability of LLMs. By identifying and addressing issues such as hallucinations, researchers can ensure that these models provide accurate and trustworthy information. This ongoing effort will contribute to the advancement of LLM technology and further expand its utility in various industries and disciplines.
The development of a new approach to mitigate LLM hallucinations represents a significant step forward in improving the reliability of these models. By enabling LLMs to evaluate their own responses and abstain from providing inaccurate or nonsensical information, the proposed method offers a valuable solution to a critical issue in language processing technology. As research in this field continues to evolve, we can expect further advancements that will enhance the capabilities and trustworthiness of LLMs, ultimately benefiting professionals and users worldwide.
Leave a Reply