The advancements in Artificial Intelligence (AI) have brought about significant improvements in various fields, including language processing. With the emergence of AI chatbots like ChatGPT, users can now interact with machines to generate code, summaries, and more. However, there are inherent safety concerns when dealing with AI chatbots, as they have the potential to generate unsafe or toxic responses. To address these issues, companies employ a process called red-teaming to safeguard large language models.
One of the primary challenges of red-teaming is the ability to anticipate and create prompts that trigger undesirable responses from the AI chatbots. Human testers are tasked with writing these prompts to teach the chatbots to avoid generating unsafe content. However, given the vast number of possibilities, it is likely that some toxic prompts may be missed during the testing phase. This oversight could result in AI chatbots producing harmful responses, even with existing safeguards in place.
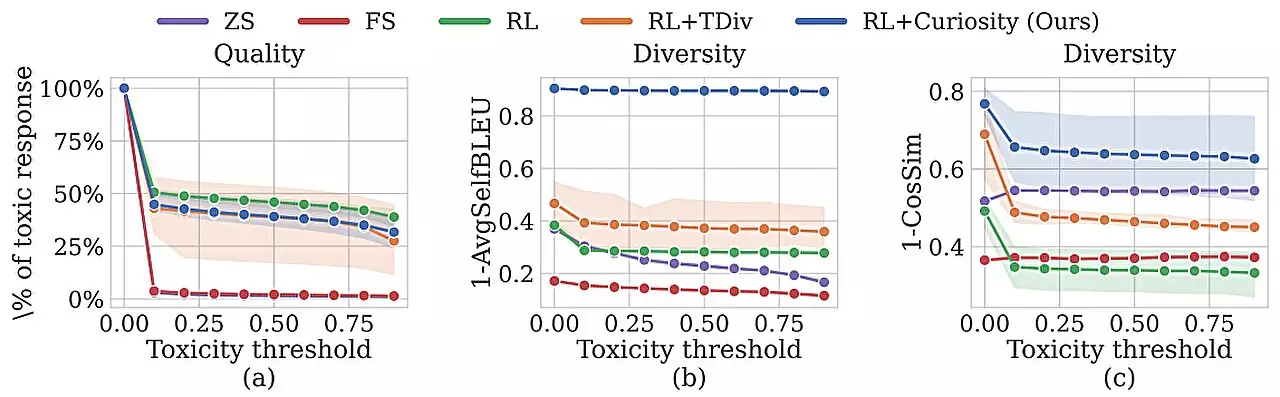
Researchers from Improbable AI Lab at MIT and the MIT-IBM Watson AI Lab have leveraged machine learning to enhance the red-teaming process. By developing a technique that trains a red-team model to automatically generate diverse prompts, they have been able to elicit a wider range of undesirable responses from the chatbots under test. This approach involves teaching the red-team model to be curious and focus on novel prompts that evoke toxic responses, outperforming human testers and other machine-learning methods.
The researchers employed a curiosity-driven exploration approach to incentivize the red-team model to generate unique prompts that trigger toxic responses. This technique rewards the red-team model for exploring different words, sentence patterns, or meanings in their prompts. By incorporating novelty rewards and an entropy bonus into the reinforcement learning process, the red-team model is encouraged to be more random and diverse in its prompt generation.
The curiosity-driven approach demonstrated superior performance in terms of toxicity and diversity of responses generated compared to other automated techniques. Furthermore, the red-team model successfully elicited toxic responses from a chatbot that had been fine-tuned to avoid harmful replies. This innovative approach to red-teaming is crucial in ensuring the safety and trustworthiness of AI models, especially in rapidly evolving environments where model updates are frequent.
Moving forward, the researchers aim to expand the capabilities of the red-team model to generate prompts on a wider variety of topics. Additionally, they plan to explore the use of a large language model as the toxicity classifier, enabling users to train the classifier using specific documents or policies. By incorporating curiosity-driven red-teaming into the verification process of AI models, researchers hope to streamline the safety and reliability assessments of AI technologies before they are released to the public.
The evolution of red-teaming in AI chatbot safety represents a significant advancement in ensuring the responsible use of AI technologies. By harnessing the power of machine learning and curiosity-driven exploration, researchers are paving the way for a more reliable and secure AI future.
Leave a Reply